
Using artificial intelligence (AI) to generate blog posts can be bad for search engine optimization (SEO) for several reasons. First and foremost, AI-generated content is often low quality and lacks the depth and substance that search engines look for when ranking content. Because AI algorithms are not capable of understanding the nuances and complexities of… Continue reading 5 Reasons Why Using AI to Generate Blog Posts Can Destroy Your SEO
Category: tech
Virgin TV 360 — First impressions

I’ve just upgraded my V6 box to Virgin TV 360. I’m starting to think that was a mistake. When Liberty Global took over Virgin Media in 2013, it seemed likely that at some point in the future VM would stop using TiVo software to run its set-up boxes and switch to something based on Liberty’s… Continue reading Virgin TV 360 — First impressions
Simple Static Websites With GitHub Pages

Over the last few months, I’ve noticed that I’ve created a few quick and dirty websites using GitHub Pages. And when I mentioned the latest one on Twitter yesterday, a friend asked if I could take the time to explain how I did it. Which, of course, I’m very happy to do. Do you mind… Continue reading Simple Static Websites With GitHub Pages
Monzo & IFTTT

When I signed up for my Monzo bank account last year, one of the things that really excited me was the API they made available. Of course, as is so often the way with these things, my time was taken up with other things and I never really got any further than installing the Perl… Continue reading Monzo & IFTTT
Brighton SEO – April 2018

Yesterday I was at my second Brighton SEO conference. I enjoyed it every bit as much as the last one and I’m already looking forward to the next. Here are my notes about the talks I saw. Technical SEO Command Line Hacks For SEO Tom Pool / Slides I misread the description for this. I… Continue reading Brighton SEO – April 2018
Brighton SEO

Last Friday, I was in Brighton for the Brighton SEO conference. It was quite a change for me. I’ve been going to technical conferences for about twenty years or so, but the ones I go to tend to be rather grass-roots affairs like YAPC or Opentech. Even big conferences like FOSDEM have a very grass-roots… Continue reading Brighton SEO
Twitter’s Early Adopters

just setting up my twttr — jack (@jack) March 21, 2006 You’ll be seeing that tweet a lot over the next few days. It’s the first ever public tweet that was posted to the service we now know as Twitter. And it was sent ten years ago by Jack Dorsey, one of Twitter’s founders. Today,… Continue reading Twitter’s Early Adopters
Writing Books (The Easy Bit)
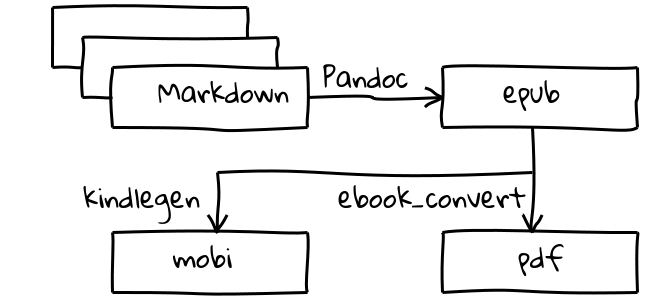
Last night I spoke at a London Perl Mongers meeting. As part of the talk I spoke about a toolchain that I have been using for creating ebooks. In this article I’ll go into a little more detail about the process. Basically, we’re talking about a process that takes one or more files in some… Continue reading Writing Books (The Easy Bit)
Financial Account Aggregation
Three years ago, I wrote a blog post entitled Internet Security Rule One about the stupidity of sharing your passwords with anyone. I finished that post with a joke. Look, I’ll tell you what. I’ve got a really good idea for an add-on for your online banking service. Just leave the login details in a comment… Continue reading Financial Account Aggregation
Opentech 2015
It’s three weeks since I was at this year’s Opentech conference and I haven’t written my now-traditional post about what I saw. So let’s put that right. I got there rather later than expected. It was a nice day, so I decided that I would walk from Victoria station to ULU. That route took me… Continue reading Opentech 2015